Skript zum Thema Funktionsparser
Diese Seite als pdf-Datei.
Inhaltsverzeichnis
1.1 Motivation
Bei der Arbeit an meinem Plotterskript für Pstricks stießich auf die
Problematik, dass ich eine Funktion mit mehreren Variablen zeichnen
wollte. Dazu schaute ich als erstes in die Dokumentation für
PST-3dplot, um zu sehen, wie es intern in Pstricks realisiert ist.
Leider gab es hier nicht die Möglichkeit einfach als Parameter
algebraic anzugeben, um in der gewohnten algebraischen Notation den
Funktionsterm aufzuschreiben.
Da ich mich nicht so recht mit der umgekehrt-polnische-Notation (UPN)
anfreunden konnte, schlug mir Stephan vor, doch einen Funktionsparser zu
schreiben, der die algebraische Notation in die umgekehrt-polnische-Notation
umwandelt. Dieses Skript eröffnet dem dem Plotterskript viele neue
Möglichkeiten eröffnet, z.B. auch die Umwandlungen beliebiger
Funktionsausdrücke in die UPN.
Tja, da stand ich nun vor einem großen Problem, was gelöst werden sollte. Wie
geht man denn da heran? Was für einen Algorithmus nutzt man dafür? Ist es
nicht doch einfacher die UPN zu lernen und sich nicht einen Algorithmus
auszudenken zu müssen? Aber man wächst ja an seinen Aufgaben...
Zu zweit spielten wir mehrere Ansätze durch, bis wir dann auf die
folgende Lösung kamen:
1.2 Der Algorithmus
Ein algebraischer Ausdruck wird zunächst in seine Einzelteile
aufgeteilt. Handelt es sich um eine Zahl mit einem Vorzeichen, eine
Rechenoperation, eine Funktion, einen Klammerterm öffnende oder schließende
Klammer?
Dies ist die Funktion des tokenizers. Die vom tokenizer
gefundenen Formelteile werden anschließend vom regelwerk schrittweise
zu größeren Termen zusammengesetzt. Dies geschieht nach den Regeln der
Mathematik, z.B. Punkt vor Strichrechnung, und wird solange wiederholt, bis
nur noch ein Term übrig bleibt oder die Funktion regelwerk einen
Fehler findet.
Die Regeln der regelwerk-Funktion sind die folgenden:
-
Ausdrücke der Form
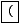

 werden in den Ausdruck
werden in den Ausdruck  verwandelt
und das Regelwerk wird rekursiv auf die
verwandelt
und das Regelwerk wird rekursiv auf die  angewendet.
angewendet.
- Ausdrücke der Form


 werden in den Term
werden in den Term  verwandelt.
verwandelt.
- Ausdrücke der Form

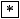
 oder
oder 
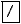
 werden in den Term
werden in den Term
 bzw.
bzw.  verwandelt.
verwandelt.
- Ausdrücke der Form

 werden in den Term
werden in den Term  verwandelt.
verwandelt.
- Ausdrücke der Form


 oder
oder 

 werden in den Term
werden in den Term
 bzw.
bzw.  verwandelt.
verwandelt.
- Ausdrücke der Form

 werden in den
Term
werden in den
Term  verwandelt.
verwandelt.
Die Funktion regelwerk sucht in jedem Durchlauf eine anwendbare Regel und führt diese aus. Dabei wird die Regel mit der kleinsten Nummer zuerst probiert. Trifft eine Regel zu, so wird diese angewendet und die Funktion startet neu mit der ersten Regel. Wenn eine Regel an mehreren Stellen anwendbar ist, so wird sie an der am weitesten links stehenden Stelle angewendet. Der Prozess wird wiederholt, bis nur noch ein Term übrig ist oder keine Regel mehr anwendbar ist. Im letzteren Fall war die Ausgangsformel nicht gültig und es wird ein Fehler ausgegeben. Mit dieser regelwerk-Funktion wird gleichzeitig parallel ein Rechenbaum aufgebaut, bei dem im Knoten immer die Operation steht. Die Blätter bestehen aus Zahlen oder Variablen. Bei den Funktionen wird der Funktionsname der Knoten und der rechte Teilbaum bleibt undefiniert. Die Funktion polnisch liefert dann die UPN, indem der aufgebaute Rechenbaum ausgelesen wird. Das Abfallprodukt des regelwerk ist ein vollständig geklammerter Rechenausdruck.
1.3 Beispiele
Hier nun ein paar Beispiele:
| Rechenausdruck | Rechenausdruck, vollständig geklammert | UPN |
2*(3+4) | (2*(3+4)) | 2 3 4 + * |
2+(x+2)^2 | (2+((x+2)^2)) | 2 x 2 + 2 ^ + |
(x+2)^2+2 | (((x+2)^2)+2) | x 2 + 2 ^ 2 + |
2+sin(2*(x+3))*3 | (2+(sin((2*(x+3))*3))) | 2 2 x 3 + * 3 * sin + |
Tab. 1: Beispiele für den Funktionsparser
1.4 Programmcode
Und hier nun der vollständige Programmcode in Perl:
| funktionsparser-pl.pl |
|---|
| #!/usr/bin/perl -w ################################################################## # # Funktionsparser # # Autoren: Stephan Hoehrmann, Xenia Rendtel # # VERSION 2 # Letzte Aenderung: 07.11.2009 # # Dieser Parser ersetzt eine Funktion in umgekehrter polnischer Notation. # dazu wird ein Baum nach dem folgenden Prinzip erstellt: # Zunaechst wird die Zeichenkette mit der Funktion tokenizer in # ihre Einzelteile zerlegt. # Dabei wird unterschieden, ob es sich um einen Term, einen Operator, # eine Funktion, eine oeffnende oder schliessende Klammer oder eine Variable handelt. # Dann wird diese neu gewonnene Liste mit dem # folgenden Algorithmus in einen Baum verwandelt: # # 0. Solange Liste nicht leer, suche von Position 0 aufsteigend # durch die Liste mit folgenden Kriterien: # 1. ( Liste ) wird zu einem Ausdruck der Form Liste ohne Klammern, # auf die der Algorithmus erneut angewendet wird. goto 0. # 2. Term|Variable ^ Term|Variable wird zu einem Term mit dem Inhalt # (Term|Variable ^ Term|Variable) # 3. Term|Variable mal|geteilt Term|Variable wird zu einem Term # mit dem Inhalt (Term|Variable mal|geteilt Term|Variable). goto 0 # 4. Funktion Term|Variable wird zu einem Term # mit dem Inhalt (Funktion Term|Variable). goto 0 # 5. Term|Variable plus|minus Term|Variable wird zu einem Term # mit dem Inhalt (Term|Variable plus|minus Term|Variable). goto 0 # 6. plus|minus Variable wird zu einem Term # mit dem Inhalt (0 plus|minus Variable). goto 0 # 7. Fertig! # Es wird dabei Schritt fuer Schritt ein Baum mit aufgebaut. ################################################################## use strict; use warnings; use Data::Dumper; use Math::Trig; use Math::Complex; use POSIX qw /floor ceil/; my @funktionpolnisch; ### Wichtige Funktionen: sub abrunden { my ( $wert, $schritt ) = @_; return $schritt * floor( $wert / $schritt ); } sub aufrunden { my ( $wert, $schritt ) = @_; return $schritt * ceil( $wert / $schritt ); } sub fakultaet { my ($n) = shift; if ( ( $n == 1 ) || ( $n == 0 ) ) { return 1; } elsif ( $n < 0 ) { return "Fehler"; } else { return $n * fakultaet( $n - 1 ); } } sub round { my ($zahl) = shift; return int( $zahl + 0.5 ); } # Die Funktion tokenizer erstellt aus einem String eine # Liste mit den einzelnen Rechenoperationen des Strings sub tokenizer { my ($text) = @_; my ( $token, $vorzeichen ); my @listevontokens; $vorzeichen = 1; $text =~ s/ //g; $text = lc($text); while ( $text ne "" ) { if ( ( $text =~ /^([-+]?[0-9]+(\.[0-9]+)?([eE][-+]?[0-9]+)?)/ ) && ( $vorzeichen == 1 ) ) { # Zahlen mit Vorzeichen $token = $1; $vorzeichen = 0; push @listevontokens, { 'Inhalt' => $token, 'Typ' => "Term", 'Baum' => { 'knoten' => $token, 'links' => undef, 'rechts' => undef } }; } elsif ( ( $text =~ /^([0-9]+(\.[0-9]+)?([eE][-+]?[0-9]+)?)/ ) && ( $vorzeichen == 0 ) ) { # Zahlen ohne Vorzeichen $token = $1; $vorzeichen = 0; push @listevontokens, { 'Inhalt' => $token, 'Typ' => "Term", 'Baum' => { 'knoten' => $token, 'links' => undef, 'rechts' => undef } }; } elsif ( $text =~ /^(\^)/ ) { # Hochzeichen $token = $1; $vorzeichen = 1; push @listevontokens, { 'Inhalt' => $token, 'Typ' => "hoch", 'Baum' => { 'knoten' => $token, 'links' => undef, 'rechts' => undef } }; } elsif ( $text =~ /^([-])/ ) { # Operatoren $token = $1; $vorzeichen = 1; push @listevontokens, { 'Inhalt' => $token, 'Typ' => "minus", 'Baum' => { 'knoten' => $token, 'links' => undef, 'rechts' => undef } }; } elsif ( $text =~ /^([+])/ ) { # Operatoren $token = $1; $vorzeichen = 1; push @listevontokens, { 'Inhalt' => $token, 'Typ' => "plus", 'Baum' => { 'knoten' => $token, 'links' => undef, 'rechts' => undef } }; } elsif ( $text =~ /^([*])/ ) { # Operatoren $token = $1; $vorzeichen = 1; push @listevontokens, { 'Inhalt' => $token, 'Typ' => "mal", 'Baum' => { 'knoten' => $token, 'links' => undef, 'rechts' => undef } }; } elsif ( $text =~ /^([:\/])/ ) { # Operatoren $token = $1; $vorzeichen = 1; push @listevontokens, { 'Inhalt' => $token, 'Typ' => "geteilt", 'Baum' => { 'knoten' => $token, 'links' => undef, 'rechts' => undef } }; } elsif ( $text =~ /^(sin|cos|tan|acos|asin|log|ln|ceiling|floor|truncate|round|sqrt|abs|fact|exp)/ ) { # Funktionen $token = $1; $vorzeichen = 1; push @listevontokens, { 'Inhalt' => $token, 'Typ' => "Funktion", 'Baum' => { 'knoten' => $token, 'links' => undef, 'rechts' => undef } }; } elsif ( $text =~ /^(\()/ ) { # oeffnende Klammer $token = $1; $vorzeichen = 1; push @listevontokens, { 'Inhalt' => $token, 'Typ' => "(", 'Baum' => { 'knoten' => $token, 'links' => undef, 'rechts' => undef } }; } elsif ( $text =~ /^(\))/ ) { # schliessende Klammer $token = $1; $vorzeichen = 0; push @listevontokens, { 'Inhalt' => $token, 'Typ' => ")", 'Baum' => { 'knoten' => $token, 'links' => undef, 'rechts' => undef } }; } elsif ( $text =~ /^([a-z][0-9a-z]*)/ ) { # Variable $token = $1; $vorzeichen = 0; push @listevontokens, { 'Inhalt' => $token, 'Typ' => "Term", 'Baum' => { 'knoten' => $token, 'links' => undef, 'rechts' => undef } }; } else { # Rest $token = $text; $vorzeichen = 1; push @listevontokens, { 'Inhalt' => $token, 'Typ' => "Rest", 'Baum' => { 'knoten' => $token, 'links' => undef, 'rechts' => undef } }; } #print "Token " . $token . "\n"; $text = substr $text, length $token; } return @listevontokens; } # Ein vollstaendig geklammerter Ausdruck wird ausgegeben. sub ausgabeliste { my (@liste) = @_; my $listenlaenge = scalar @liste; my $i; printf("'"); for ( $i = 0 ; $i < $listenlaenge ; $i++ ) { printf( "%s", $liste[$i]{'Inhalt'} ); printf(" ") if ( $i < $listenlaenge - 1 ); } print "'\n "; } # Der eigentliche Algorithmus sub regelwerk { my (@liste) = @_; my ( @klammerterm, $i, $j, $gefunden, $klammerauf, $klammerzu, $klammertiefe ); do { $gefunden = 0; if ( !$gefunden ) { $klammerzu = $klammerauf = $klammertiefe = 0; # Klammern: # Wenn eine oeffnende Klammer gefunden wurde, dann wird der Zaehler klammertiefe erhoeht, # bei einer schliessenden Klammer erniedrigt. # Bei korrekter Klammerung ist der Zaehler am Ende 0 # und es wird die regelwerk-Funktion auf den Inhalt der Klammer angewendet. for ( $i = 0 ; $i < scalar @liste ; $i++ ) { if ( $liste[$i]{'Typ'} eq "(" ) { if ( ( $klammertiefe == 0 ) ) { $klammerauf = $i; } $klammertiefe++; } if ( $liste[$i]{'Typ'} eq ")" ) { $klammertiefe--; if ( $klammertiefe == 0 ) { $klammerzu = $i; } } } ## Fehler wenn klammertiefe != 0 muss noch bearbeitet werden if ( $klammerauf != $klammerzu ) { @klammerterm = (); for ( $j = $klammerauf + 1 ; $j <= $klammerzu - 1 ; $j++ ) { push @klammerterm, { 'Inhalt' => $liste[$j]{'Inhalt'}, 'Typ' => $liste[$j]{'Typ'}, 'Baum' => { 'knoten' => $liste[$j]{'Baum'}{'knoten'}, 'links' => undef, 'rechts' => undef } }; } splice( @liste, $klammerauf, $klammerzu - $klammerauf + 1, regelwerk(@klammerterm) ); $gefunden = 1; } } if ( !$gefunden ) { # Potenzieren for ( $i = 0 ; $i < scalar @liste - 2 ; $i++ ) { if ( ( $liste[$i]{'Typ'} eq "Term" ) && ( $liste[ $i + 1 ]{'Typ'} eq "hoch" ) && ( $liste[ $i + 2 ]{'Typ'} eq "Term" ) && ( !$gefunden ) ) { splice( @liste, $i, 3, { 'Inhalt' => "(" . $liste[$i]{'Inhalt'} . $liste[ $i + 1 ]{'Inhalt'} . $liste[ $i + 2 ]{'Inhalt'} . ")", 'Typ' => "Term", 'Baum' => { 'knoten' => $liste[ $i + 1 ]{'Baum'}{'knoten'}, 'links' => $liste[$i]{'Baum'}, 'rechts' => $liste[ $i + 2 ]{'Baum'} } } ); $gefunden = 1; } } } if ( !$gefunden ) { # Multiplikation und Division for ( $i = 0 ; $i < scalar @liste - 2 ; $i++ ) { if ( ( $liste[$i]{'Typ'} eq "Term" ) && ( ( $liste[ $i + 1 ]{'Typ'} eq "mal" ) || ( $liste[ $i + 1 ]{'Typ'} eq "geteilt" ) ) && ( $liste[ $i + 2 ]{'Typ'} eq "Term" ) && ( !$gefunden ) ) { splice( @liste, $i, 3, { 'Inhalt' => "(" . $liste[$i]{'Inhalt'} . $liste[ $i + 1 ]{'Inhalt'} . $liste[ $i + 2 ]{'Inhalt'} . ")", 'Typ' => "Term", 'Baum' => { 'knoten' => $liste[ $i + 1 ]{'Baum'}{'knoten'}, 'links' => $liste[$i]{'Baum'}, 'rechts' => $liste[ $i + 2 ]{'Baum'} } } ); $gefunden = 1; } } } if ( !$gefunden ) { # Funktion for ( $i = 0 ; $i < scalar @liste - 1 ; $i++ ) { if ( ( $liste[$i]{'Typ'} eq "Funktion" ) && ( $liste[ $i + 1 ]{'Typ'} eq "Term" ) && ( !$gefunden ) ) { if ( $liste[$i]{'Inhalt'} eq "exp" ) { splice( @liste, $i, 2, { 'Inhalt' => "(" . exp(1) . "\^" . $liste[ $i + 1 ]{'Inhalt'} . ")", 'Typ' => "Term", 'Baum' => { 'knoten' => "^", 'links' => { 'knoten' => exp(1), 'links' => undef, 'rechts' => undef }, 'rechts' => $liste[ $i + 1 ]{'Baum'} } } ); } else { splice( @liste, $i, 2, { 'Inhalt' => "(" . $liste[$i]{'Inhalt'} . $liste[ $i + 1 ]{'Inhalt'} . ")", 'Typ' => "Term", 'Baum' => { 'knoten' => $liste[$i]{'Baum'}{'knoten'}, 'links' => $liste[ $i + 1 ]{'Baum'}, 'rechts' => undef } } ); } $gefunden = 1; } } } if ( !$gefunden ) { # Addition und Subtraktion for ( $i = 0 ; $i < scalar @liste - 2 ; $i++ ) { if ( ( $liste[$i]{'Typ'} eq "Term" ) && ( ( $liste[ $i + 1 ]{'Typ'} eq "plus" ) || ( $liste[ $i + 1 ]{'Typ'} eq "minus" ) ) && ( $liste[ $i + 2 ]{'Typ'} eq "Term" ) && ( !$gefunden ) ) { splice( @liste, $i, 3, { 'Inhalt' => "(" . $liste[$i]{'Inhalt'} . $liste[ $i + 1 ]{'Inhalt'} . $liste[ $i + 2 ]{'Inhalt'} . ")", 'Typ' => "Term", 'Baum' => { 'knoten' => $liste[ $i + 1 ]{'Baum'}{'knoten'}, 'links' => $liste[$i]{'Baum'}, 'rechts' => $liste[ $i + 2 ]{'Baum'} } } ); $gefunden = 1; } } } if ( !$gefunden ) { # Term mit Vorzeichen for ( $i = 0 ; $i < scalar @liste - 1 ; $i++ ) { if ( ( ( $liste[$i]{'Typ'} eq "plus" ) || ( $liste[$i]{'Typ'} eq "minus" ) ) && ( $liste[ $i + 1 ]{'Typ'} eq "Term" ) ) { splice( @liste, $i, 2, { 'Inhalt' => "(0" . $liste[$i]{'Inhalt'} . $liste[ $i + 1 ]{'Inhalt'} . ")", 'Typ' => "Term", 'Baum' => { 'knoten' => $liste[$i]{'Baum'}{'knoten'}, 'links' => { 'knoten' => 0, 'links' => undef, 'rechts' => undef }, 'rechts' => $liste[ $i + 1 ]{'Baum'} } } ); $gefunden = 1; } } } } while ($gefunden); ausgabeliste(@liste); return @liste; } # polnische Notation wird ausgegeben. sub polnisch { my $ref = shift; # suche links (rekursiv) if ( defined( $$ref{'links'} ) ) { polnisch( $$ref{'links'} ); } # suche rechts (rekursiv) if ( defined( $$ref{'rechts'} ) ) { polnisch( $$ref{'rechts'} ); } # Ausgabe des Knotens print " $$ref{'knoten'}"; } sub rechenbaum_ausrechnen { my $baum = shift; my $variablen = shift; print $$baum{'knoten'} . "\n"; if ( $$baum{'knoten'} eq "*" ) { return rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) * rechenbaum_ausrechnen( $$baum{'rechts'}, $variablen ); } elsif ( $$baum{'knoten'} eq ":" ) { return rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) / rechenbaum_ausrechnen( $$baum{'rechts'}, $variablen ); } elsif ( $$baum{'knoten'} eq "/" ) { return rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) / rechenbaum_ausrechnen( $$baum{'rechts'}, $variablen ); } elsif ( $$baum{'knoten'} eq "+" ) { return rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) + rechenbaum_ausrechnen( $$baum{'rechts'}, $variablen ); } elsif ( $$baum{'knoten'} eq "^" ) { return rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) **rechenbaum_ausrechnen( $$baum{'rechts'}, $variablen ); } elsif ( $$baum{'knoten'} eq "-" ) { return rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) - rechenbaum_ausrechnen( $$baum{'rechts'}, $variablen ); } elsif ( defined $$variablen{ $$baum{'knoten'} } ) { return $$variablen{ $$baum{'knoten'} }; } elsif ( $$baum{'knoten'} eq "sin" ) { return sin( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) ); } elsif ( $$baum{'knoten'} eq "cos" ) { return cos( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) ); } elsif ( $$baum{'knoten'} eq "tan" ) { return tan( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) ); } elsif ( $$baum{'knoten'} eq "asin" ) { return arcsin( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) ); } elsif ( $$baum{'knoten'} eq "acos" ) { return acos( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) ); } elsif ( $$baum{'knoten'} eq "log" ) { return log( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) ); } elsif ( $$baum{'knoten'} eq "ceiling" ) { return aufrunden( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ), 1 ); } elsif ( $$baum{'knoten'} eq "floor" ) { return abrunden( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ), 1 ); } elsif ( $$baum{'knoten'} eq "truncate" ) { if ( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) < 0 ) { return aufrunden( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ), 1 ); } else { return abrunden( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ), 1 ); } } elsif ( $$baum{'knoten'} eq "round" ) { return round( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) ); } elsif ( $$baum{'knoten'} eq "sqrt" ) { return sqrt( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) ); } elsif ( $$baum{'knoten'} eq "abs" ) { return abs( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) ); } elsif ( $$baum{'knoten'} eq "fact" ) { return fakultaet( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) ); } elsif ( $$baum{'knoten'} eq "exp" ) { return exp( rechenbaum_ausrechnen( $$baum{'links'}, $variablen ) ); } else { # ACHTUNG: Keine Fehlerbehandlung!!! return $$baum{'knoten'}; } } sub funktionsausgabe { my $funktionsausdruck = shift; my @ergebnis = regelwerk( tokenizer($funktionsausdruck) ); if ( scalar @ergebnis != 1 ) { printf("Fehler \n"); ausgabeliste(@ergebnis); } else { polnisch( $ergebnis[0]{'Baum'} ); print "\n"; } } my @ergebnis = regelwerk( tokenizer("(x-2)*(x+2)") ); print rechenbaum_ausrechnen( $ergebnis[0]{'Baum'}, { 'x' => 2, 'y' => 2, 'pi' => pi() } ) . "\n"; funktionsausgabe("x*x*-3"); |
Literatur
- [Krienke, 2002]
- Krienke, Rainer (2002). Programmieren in Perl.. Hanser Fachbuchverlag, 2., erw .
Letzte Änderung: 07.07.2015: 21:32:58 von X. Rendtel

Dieses Werk bzw. Inhalt steht unter einer Creative Commons Namensnennung-Weitergabe unter gleichen Bedingungen 3.0 Unported Lizenz.
Beruht auf einem Inhalt unter www.rendtel.de.